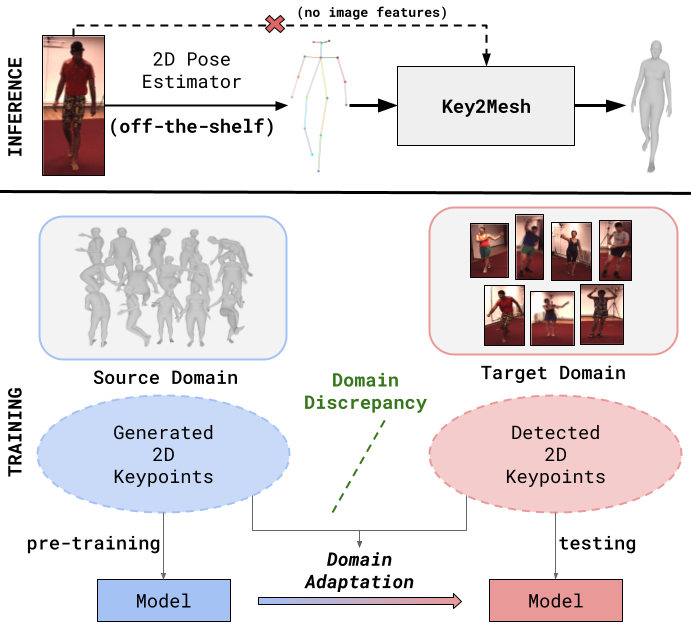
An overview of Key2Mesh's inference and training process.
@InProceedings{Uguz_2024_CVPR,
author = {Uguz, Bedirhan and Suat, Ozhan and Karagoz, Batuhan and Akbas, Emre},
title = {MoCap-to-Visual Domain Adaptation for Efficient Human Mesh Estimation from 2D Keypoints},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2024},
pages = {1622-1632}
}